
近日,英国皇家学会(Royal Society)发布了一份题为《机器学习:能通过样本进行学习的计算机的力量与希望(Machinelearning: the power and promise of computers that learn by example)》的专题报告。
以机器学习为代表的人工智能技术是当下最为热门的技术研究方向之一,其被认为对经济、社会、科学等都会有颠覆性的重大影响。
该报告对机器学习进行了较为全面的概述,其中涉及到机器学习的基本概念、发展历程、应用、创造价值的方式和研究前沿等。
值得一提的是,该报告的参与团队阵容非常强大,其中包括 Uber 的首席科学家 Zoubin Ghahramani 教授、Google DeepMind 的联合创始人兼 CEO Demis Hassabis 博士和亚马逊机器学习主管 Neil Lawrence 教授等。、
本文对其中机器学习和人工智能的发展历史、机器学习的典型问题及现有方法的局限性进行了翻译,带领读者对机器学习和人工智能进行初步认识。
机器学习和人工智能的发展
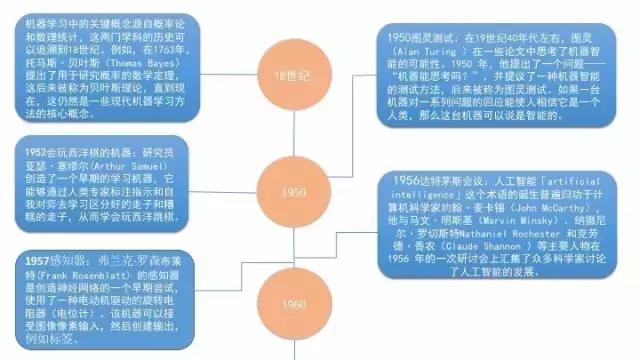
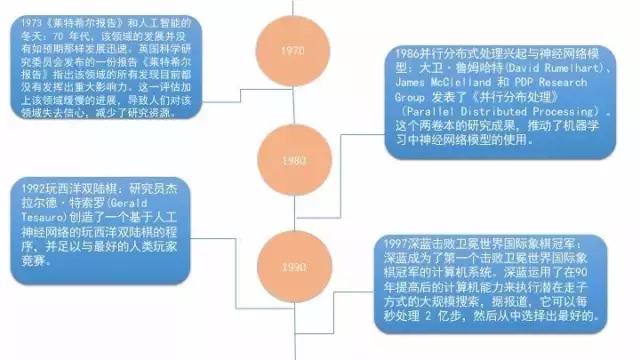
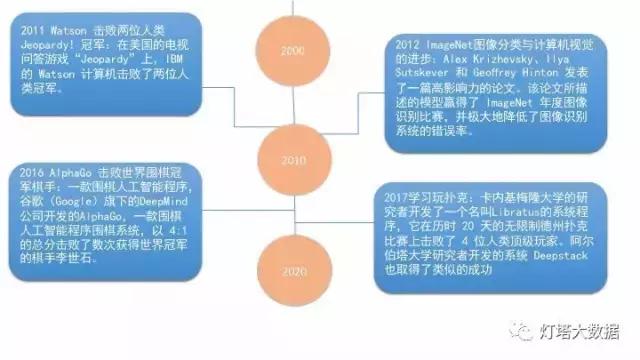

机器学习中的典型问题
机器学习可以运用数据分析去检测模型,并在这些基础上进行预测。
怎样将机器学习运用在实践中?以各种方式运用不同的模型去分析数据(见第1.3节),下面是机器学习如何通过神经网络检测字迹的一个例子。
例子:通过神经网络检测字迹
机器学习在笔迹检测这个领域有着极高的准确率。神经网络就是其中一种方法,将各层计算单元相连接,这受到了大脑内部神经元连接方式的启发。
输入单元接受外部世界的信息,而输出层输出关于输入数据的决定。其他层的主要贡献是输入数据的各层传输。
在手写识别中,特征抽取系统通过识别每个字母的构成元素来学习字母的特点。
例如,如果一条短横线垂直于一条竖线,这很可能是L。通过创建每个字母的组成规则, 系统能够学习每个字母的关键特征, 通过组成特征来识别每个手写字符。
特征识别的启用可以让神经网络在大量书写文本中得到训练。经过训练之后,这个系统可以检测新的文本之中的相关特征,然后决定它面前的文本是哪一个字母。
在训练之中,反向传播算法可以提高系统的准确性,通过比较系统输出(系统预测的字母)和真正的输出(用户定义)的,计算两者的不同,优化权值来提高准确率。

现有方法的局限
尽管近年来取得了很多进展,机器学习的使用仍然受到限制。例如,一些机器学习的方法依靠大量标签数据,而这些数据的创建和管理需要大量的资源和时间。
赋予系统理解上下文的能力或者常识,较为困难。当专业知识失灵时,人们往往依靠常识而采取行动,尽管这不是最优选择,但不会造成重大损失。
当前的机器学习系统并不能定义或者编码这种行为,这就意味着当系统遭遇失败时,很可能会引发一连串的失败。
人类善于将解决问题的办法从一个领域转移到另外一个领域,这对掌握了最新机器学习技能的计算机而言仍然是一个挑战。
可解释性是问题域之间的信息转移的一大挑战。可解释性也可以看作是如何将学习系统中以编码呈现的知识以一种简单易懂的方式呈现出来。
在现实中有很多约束条件,例如自然法则(物理现象)和数学规律(逻辑),这些约束条件很难融入进机器学习之中。如果能将约束条件编入程序,我们在学习中就能更加高效地利用数据。
弄清人类的意图是十分复杂的,首先就要对我们自己有一个深刻的了解。当前的方法对于人类的理解还是有限的,特别是在某些领域内。
这就带来了一些挑战,例如在协同环境里的机器人助手以及无人驾驶汽车。在这些领域内,重大的技术进步,将会打破这些局限限。
End.
侵删











文章评论
0条